
本文聚焦如何通过 Hadoop Streaming + Python 编写 Hadoop 程序。
众所周知,实现分布式计算是一个繁琐的过程。Hadoop 通过一个标准化的数据处理流程,简化操作步骤,让没有分布式计算背景的程序员也能轻松写出分布式程序。Hadoop 本身是用 Java 写的,因此对于非 Java 程序员来说,学 Hadoop 必须先学 Java,这大大降低了 Hadoop 的友好程度。
Hadoop Streaming 就是为了解决这个问题而生的,它支持用其他编程语言编写 Hadoop 程序。
1. 分布式系统的由来
经历半个多世纪的高速增长,半导体工业在本世纪初触及了它的物理瓶颈,摩尔定律失灵,硬件算力不再高速增长,人们开始关注利用软件方法来提升算力。
2003年,两名谷歌工程师开发了一个分布式存储系统,这是它的前身。经过几位后来者添枝加叶,该系统在 2006 年开源,并发展成为今天我们熟知的 Hadoop。
使用分布式系统,显而易见的好处是能够缩短程序运行的时间。在常规时间就能跑完的程序上使用 Hadoop 无异于画蛇添足。但是对大数据开发人员来说,使用 Hadoop 意味着不必坐在电脑前为了结果等上一整天。如果集群效率够高,完全可能在几分钟内完成单机一天的计算量。
2. Hadoop 基本介绍
Hadoop 有两个重要的组成部分:HDFS 和 MapReduce。
HDFS 是一个分布式存储系统,它负责将文件切割成分片,然后分发到集群中的目标机器上进行存储;MapReduce 负责构建一个标准化的数据处理流程,在完成其规定的几道数据处理流程之后,用户将得到他们期望的结果。
这意味着 Hadoop 的学习至少包括两个部分。要掌握 HDFS,你需要掌握 Hadoop 命令行命令,这将在第7节详细介绍。要掌握 MapReduce,如果你是 Python 开发者,你需要掌握 Hadoop Streaming,这将在下一节中介绍。
3. MapReduce
MapReduce 的重要性不言而喻,它定义了数据在 Hadoop 中被如何处理。MapReduce 包含三个重要过程:Map, Shuffle 和 Reduce。其中,Map 和 Reduce 由我们来编写,Shuffle 则由系统自动完成。
3.1 Map, Shuffle 和 Reduce
下面这张流程图展示了这三道数据处理工序在整个数据处理流中的位置。
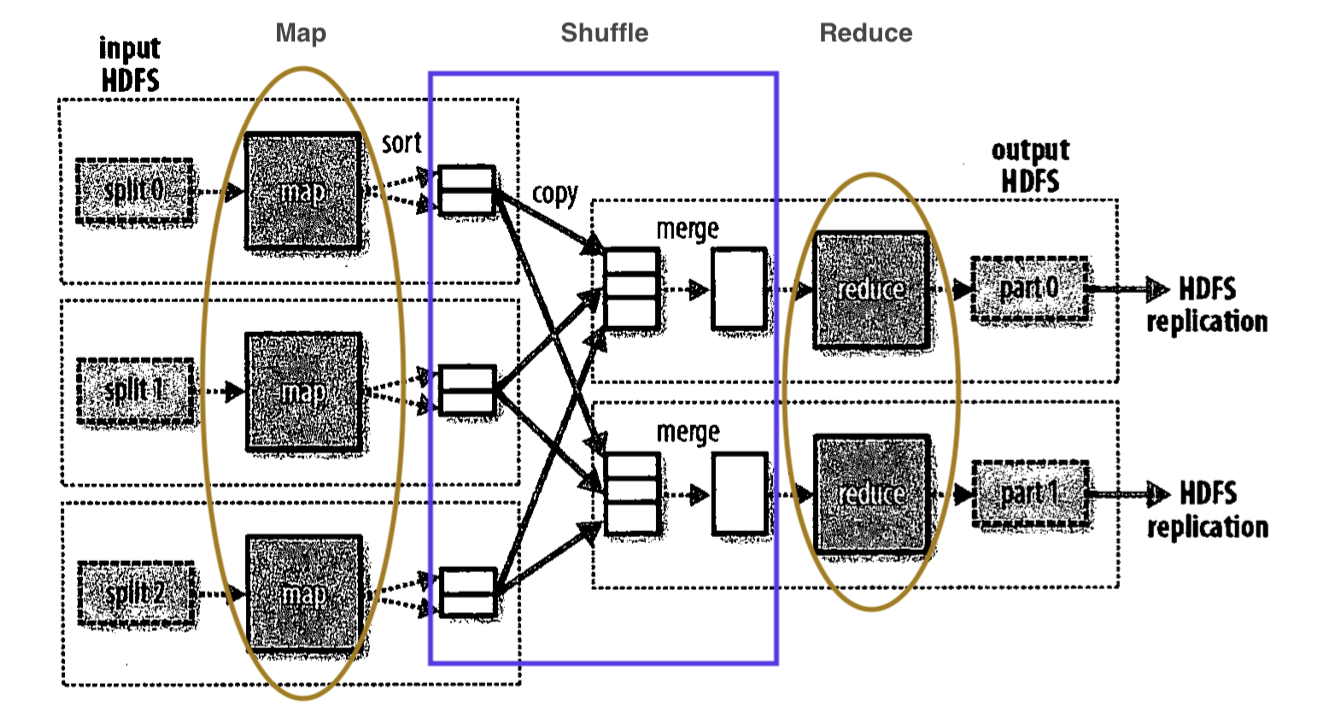
观察这张图,我们发现数据首先被切割 (split),然后被分发到 Map,之后又经历 sort 和 merge 步骤,接着来到 Reduce,最后输出到 HDFS 上。
这种工序经过了严密设计,是为了尽可能多地保持适应力,使其在能够适应各种数据处理需求的同时,又能兼顾效率。它保证了多数需求,在这种框架下,都能被适当处理。
Map, Shuffle 和 Reduce 三阶段的作用分别是:
-
Map:预处理。Shuffle 通常要耗费大量计算资源,因此传给 Shuffle 的数据越精简越好,这就要求我们在 Mapper 阶段把和研究问题无关的数据都丢掉。在本阶段的输出中,我们必须定义好主键。
-
Shuffle:Shuffle 的内涵包括两个部分:排序 (Sort) 和 分桶 (Partition)。Shuffle 首先对 Mapper 传来的数据按主键进行排序,继而将其分桶。分桶指将已排数据切割成分片,并将其发送给 Reducer。
- Reduce: 不知道怎么翻译,我翻译成“规约”。它就是将冗杂的数据,规约成用户期望、感兴趣的数据结果。这种数据结果可能是一个或者一组统计量,也可能是输入数据的处理结果。
3.2 kv 表:数据传输的格式
数据在上述三个处理阶段之间,是以 kv表 为数据传输格式的。kv 表由 key(主键)和 value 组成,key 和 value 都可以包含一个或多个字段。
kv 表在 Unix 中长这样👇。每行数据中的各字段以制表符 \t 为分隔。
dogs 1 happy
cats 3 happy
pigs 2 sleeping
cats 1 sad
3.3 实例:WordCount
为了说明数据在 Hadoop 中是如何被处理的。我们引入一个实例 WordCount 来讲解。WordCount 是一个简单的数据处理任务,它要求我们统计文章中每个单词出现的频率。
本来我们只要几行 Python 代码就能完成 👇
# word_count.py
# usage: cat test_file.txt | python word_count.py
import sys
import collections
words_dict = collections.defaultdict(int)
for line in sys.stdin:
line = line.strip().split(' ')
if not line:
continue
for word in line:
words_dict[word] += 1
for k, v in words_dict.items():
print('{}: {}'.format(k, v))
换成 Hadoop 的写法,它会变得很冗长。但回馈就是,在数据量庞大的情况下,原本需要巨量时间的任务,现在能在短时间内完成。
☆ Hadoop 方法:
在贴上代码之前,我们先来看看 Hadoop 是如何一步步将数据改造成我们期望的模样的。
- 这是原始数据。
i love you you love him he loves her she loves him - 首先将数据切割成多个分片 (split 阶段)。
# part_1 i love you you love him ✄ ----------------- # part_2 he loves her she loves him - 将各个分片分别送入各自的 Mapper 中做预处理,然后返回以单词为主键的 kv 表 (map 阶段)。
# part_1 i 1 love 1 you 1 you 1 love 1 him 1 ✄ ----------------- # part_2 he 1 loves 1 her 1 she 1 loves 1 him 1 - 按主键排序后分桶 (shuffle 阶段)。
# part_1 he 1 her 1 him 1 him 1 i 1 ✄ ----------------- # part_2 love 1 love 1 loves 1 loves 1 she 1 you 1 you 1 - 将数据捏成我们想要的形状 (reduce 阶段)。
# part-00000 he 1 her 1 him 2 i 1 ✄ ----------------- # part-00001 love 2 loves 2 she 1 you 2
经历上述步骤后,我们会得到两个文件:part-00000 和 part-00001。得到文件的数量和 reducer 数相同。因本例有两个 reducer,故我们最终得到两个输出文件。
4. 用 Python 开发 MapReduce
嘟噜噜,下面开始写 MapReduce 代码。
因为我懒,不想重复写代码,所以这里贴上 Writing An Hadoop MapReduce Program In Python 的代码原文。这篇文章本身也非常好,推荐大家看看 
mapper
#!/usr/bin/env python
"""mapper.py"""
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
reducer
#!/usr/bin/env python
"""reducer.py"""
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
5. 启动脚本
只有 Mapper 和 Reducer 没用啊,Hadoop 要从命令行启动,因此我们还需要一个 bash 脚本帮我们启动 Hadoop。
hadoop streaming \
-D mapred.job.priority=VERY_HIGH \
-D stream.num.map.output.key.fields=4 \
-D num.key.fields.for.partition=1 \
-input myInputDirs \
-output myOutputDir \
-mapper "python mapper.py" \
-reducer "python reducer.py" \
-file "./mapper.py" \
-file "./reducer.py" \
-file "./additional_file.txt" \
-jobconf mapred.job.name="yourJobName" \
-jobconf mapred.reduce.tasks=100 \
-jobconf mapred.job.map.capacity=2000 \
-jobconf mapred.job.reduce.capacity=300 \
-jobconf mapred.map.over.capacity.allowed=true \
-jobconf mapred.reduce.over.capacity.allowed=true \
参数 reduce.tasks 有时设为 1 (-jobconf mapred.reduce.tasks=1),这样最终输出的文件数也为1。虽然这个设置会影响性能,但由于输出文件只有1个的缘故,输出文件不需要额外的 merge 处理,在 reducer 压力不大时可以考虑。
6. 测试
即使是 Hadoop 集群,在处理超大数据集的时候,跑一两个小时也是惯常现象。如果你的程序因为有 bug 运行中止,那你就亏大了。因为你又得 debug,然后重跑。
为了避免这种情况出现,测试是必要的。我一般会按照这个流程进行测试:
- code review
- local test
- check try except
Code review 的作用就是,看一样程序,然后确认“这个程序看起来没什么问题”。这能有效阻挡大部分显而易见的错误。
Local test 是本地小数据集测试。开始前要先构造数据文件 test_file,然后用 cat test_file | python mapper.py | sort | python reducer.py 命令在本地运行测试。这主要是为了测试语法的正确性;
Check try except 指检查是否写了充分的 try except 语句来处理可能出现的异常,例如字段缺失、数据类型异常、数值异常等等。因为代码需要经受住大数据量的考验,因此对健壮性的要求很高。
7. 文件操作
Hadoop 通过 HDFS (Hadoop Distributed File System) 来管理集群上的文件。
常见的文件操作命令:
# 查看帮助文档
hadoop fs -help
# 查看当前文件夹的文件
hadoop fs -ls
# 下载文件到本地
hadoop fs -copyToLocal [hdfs路径] [本地路径]
# 上传文件到HDFS
hadoop fs -copyFromLocal [本地路径] [hdfs路径]
# 新建HDFS目录
hadoop fs -mkdir [hdfs路径]
# 删除HDFS文件
hadoop fs -rm [hdfs路径]
8. 只言片语
Hadoop MapReduce 是一套编程模型,基本思路是先把数据切成不同分片,然后基于键值对排序并在机器间交换一次数据,再然后按主键对数据分桶,最后规约到结果。这套模式是死的,也就是你只能按照既定的运算框架和运算顺序来处理数据。
既然模式是死的,就一定存在一部分问题天然不适合用 Hadoop 解决。具体到每个问题,Hadoop 的适用程度都是不一样的。有些本来不合适但又不得不用的项目,我们还是得拆分需求、设计运算流程,尽量地去贴合 MapReduce 这套模型。需求拆得对不对,流程设计得好不好,在很大程度上会影响程序的运行效率。
参考文献: