
本来我懒得装,但是 MySQL 太慢了,遭不住,咱还是把 ClickHouse 装起来吧。
GitHub 项目地址:chat-to-clickhouse
在《Agent 实战:智能路由、任务拆解和链路工程》一文中,我实现了一个简单的 ChatBI,它能查询 MySQL 数据库。对于小批量数据量,MySQL 尚可应付,但是当数据量来到千万量级时,一次 MySQL 查询将消耗数秒甚至数十秒,这么长的等待时间是用户难以忍受的。而且 Agent 还有一个技术问题,它的 NL2SQL 尚未做到 one-shot,也就是说,在拿到最终结果前,它也许需要多次试错,这将进一步拉长查询时间。
如何无痛解决查询效率低下的问题呢?很简单,只需要换数据库就可以做到。这便引入今天的主角:ClickHouse。
一、分析利器
ClickHouse 是 Yandex 旗下的一款开源的列式存储数据库,专为 联机分析处理 (OLAP) 场景设计。在做数据分析时,它比传统数据库快几倍到几十倍。分析场景的核心需求是「聚合计算」,即 GROUP BY 子句下的 SUM, AVG, COUNT 操作,这些正是 ClickHouse 的强项。
为什么它的聚合计算如此之快呢?因为它具有如下特性:
- 列式存储:顾名思义,列存的数据是按列存储的。这种存储方式可以减少无效 I/O,因为列存可以只读取查询中涉及的列。而非行存那样,读取整行后再丢掉不需要的列
- 并行计算:列存的另一个优势是数据更容易切分。单列数据的连续性和同构性更强,无需考虑与其他列的关联,因此可以更方便地按维度(如时间区间、数值分段)拆分并分配到不同节点。当然,这种设计的代价是使得插入操作变得更加昂贵
- 物化视图:物化视图可以把高频分析的结果提前算好存在表里,后续查询直接读结果,无需重新计算
二、安装过程
用 Docker 安装,过程相对简单。工业界在集群上装,比咱们这个复杂不少。
1. 配置 Docker 镜像源
中国大陆地区下载镜像,需要配置镜像源。
对于 Linux 系统,需要在 /etc/docker/daemon.json 文件中配置镜像源(如下)。Windows 和 MacOS 系统更方便一点,可以直接在 Docker Desktop 的 Settings -> Docker Engine 页面修改 daemon.json 文件。
在 daemon.json 文件中,添加镜像源字段 registry-mirrors:
{
"experimental": false,
"registry-mirrors": [
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
]
}
运行以下命令重启 Docker,配置将在重启后生效:
sudo systemctl restart docker
Note: 镜像源网站通常有个白名单,只有白名单里的镜像才能下载到。如果你需要的镜像比较新或者比较冷门,那就需要借助某些科技了 (ノ)`ε´(ヾ)
2. 安装 ClickHouse
1)拉取镜像
# 下载镜像
docker pull clickhouse/clickhouse-server
# 下载完成后,查看所有镜像的列表,看下 clickhouse 在不在里面
docker images
2)启动容器
在下面的命令中,我创建了一个名为 admin 的账户,当然你可以用其他名字。注意下面的 [YOUR_PASSWORD_HERE] 只是个占位符,请用「你的密码」替换它。
# 打开工程目录,如果没有请先新建:mkdir chat-to-clickhouse
cd chat-to-clickhouse
# 启动容器
docker run -d \
--name clickhouse-server \
-p 18123:8123 \
-p 19000:9000 \
-v $(pwd)/ch_data:/var/lib/clickhouse/ \
-v $(pwd)/ch_logs:/var/log/clickhouse-server/ \
-e CLICKHOUSE_USER=admin \
-e CLICKHOUSE_PASSWORD=[YOUR_PASSWORD_HERE] \
--ulimit nofile=262144:262144 \
--cap-add=SYS_NICE \
--cap-add=IPC_LOCK \
clickhouse/clickhouse-server
# 查看容器日志
docker logs clickhouse-server
3)检查安装
尽管 ClickHouse 现在没有数据,我们仍可通过一些简单的查询,检查服务是否已经开启。注意把下面的 [YOUR_PASSWORD_HERE] 换成你的真实密码哦。
# 检查连通性,正常情况输出:Ok.
curl -u admin:[YOUR_PASSWORD_HERE] "http://localhost:18123/"
# 查询数据库版本
curl -u admin:[YOUR_PASSWORD_HERE] "http://localhost:18123/?query=SELECT%20version()"
三、写入数据
向 ClickHouse 写入数据的方法很多。你可以从 MySQL 数据库迁移,也可以用 CSV 文件导入。下面我用一些例子展示如何导入数据。
打开命令行,登录 ClickHouse 客户端:
# 登录 ClickHouse 客户端
docker exec -it clickhouse-server \
clickhouse-client \
--user admin \
--password [YOUR_PASSWORD_HERE]
1. 从 CSV 文件导入
为了后面有数据可玩,这里我们真的向 ClickHouse 里写入数据。
我找来一份大家都很感兴趣的数据,开源动漫数据集 top-popular-anime。大家可以自行前往 Kaggle 下载 popular_anime.csv。
老规矩我们先建库建表:
-- 创建库
CREATE DATABASE IF NOT EXISTS entertainment;
-- 创建表
CREATE TABLE IF NOT EXISTS entertainment.anime_info (
id UInt32 COMMENT '动画唯一标识ID',
name String COMMENT '动画名称',
genres String COMMENT '动画类型',
type String COMMENT '播出形式',
episodes Float32 COMMENT '集数',
status String COMMENT '播出状态',
aired_from DateTime COMMENT '开始播出时间',
aired_to DateTime COMMENT '结束播出时间',
duration_per_ep String COMMENT '单集时长',
score Float32 COMMENT '评分',
scored_by Float64 COMMENT '评分人数',
`rank` Float32 COMMENT '排名',
rating String COMMENT '年龄分级',
studios String COMMENT '制作工作室',
producers String COMMENT '出品方',
image String COMMENT '封面图片URL',
trailer String COMMENT '预告片URL',
synopsis String COMMENT '剧情简介'
)
ENGINE = MergeTree()
ORDER BY (`id`)
COMMENT '动画信息数据表';
先将 popular_anime.csv 文件复制到容器挂载的数据卷 ch_data 上:
cp /path/to/popular_anime.csv ./ch_data/user_files/
再将 CSV 数据导入 ClickHouse 数据库:
-- 将 csv 文件导入 clickhouse
INSERT INTO entertainment.anime_info
SELECT
id,
name,
genres,
type,
episodes,
status,
toDateTime(replaceRegexpAll(aired_from, 'T|\\+.*', ' ')) AS aired_from,
toDateTime(replaceRegexpAll(aired_to, 'T|\\+.*', ' ')) AS aired_to,
duration_per_ep,
score,
scored_by,
`rank`,
rating,
studios,
producers,
image,
trailer,
synopsis
FROM file('popular_anime.csv', 'CSVWithNames');
-- 检查导入是否成功
SELECT * FROM entertainment.anime_info LIMIT 2;
-- 看一下行数
SELECT count(*) FROM entertainment.anime_info;
2. 从 MySQL 导入
进入客户端,创建 ClickHouse 数据库和数据表:
-- 创建库
CREATE DATABASE IF NOT EXISTS [CH_DB];
-- 创建表
CREATE TABLE IF NOT EXISTS [CH_DB].[CH_TABLE] (
`key` String NOT NULL COMMENT '标识',
`value` String COMMENT '内容',
`update_time` Date COMMENT '更新日期'
)
ENGINE = MergeTree()
PARTITION BY update_time
ORDER BY (`key`)
COMMENT 'xxx数据表';
然后用以下命令,将 MySQL 数据插入建好的 ClickHouse 数据表:
# 从 MySQL 数据库迁移数据
INSERT INTO [CH_DB].[CH_TABLE]
SELECT
`key`,
`value`,
`update_time`
FROM mysql(
'[MYSQL_HOST]:[MYSQL_PORT]',
'[MYSQL_DB]',
'[MYSQL_TABLE]',
'[MYSQL_USER]',
'[MYSQL_PASSWORD]'
);
四、Python 获取 ClickHouse 数据
安装 clickhouse-connect:
pip install clickhouse-connect
运行 Python 代码,记得将 [YOUR_PASSWORD_HERE] 换成你的密码。
import clickhouse_connect
# 创建 ClickHouse 客户端连接
client = clickhouse_connect.get_client(
host='localhost', # Docker 宿主机 IP
port=18123, # ClickHouse HTTP 端口
username='admin', # 用户名
password='[YOUR_PASSWORD_HERE]', # 密码
database='entertainment' # 数据库名
)
query = "SELECT * FROM entertainment.anime_info LIMIT 3"
try:
# 执行 SQL 查询
result = client.query(query)
# 打印查询结果
print("查询结果:")
for row in result.named_results():
print(row)
# 获取表结构信息
schema_result = client.query("DESCRIBE entertainment.anime_info")
print("\n表结构:")
for column in schema_result.named_results():
print(f"{column['name']}: {column['type']}")
except Exception as e:
print(f"查询出错: {e}")
finally:
client.close()
五、ChatBI 访问 ClickHouse 数据
下面是提问「评分人数最多的十部动漫是?」的回答。
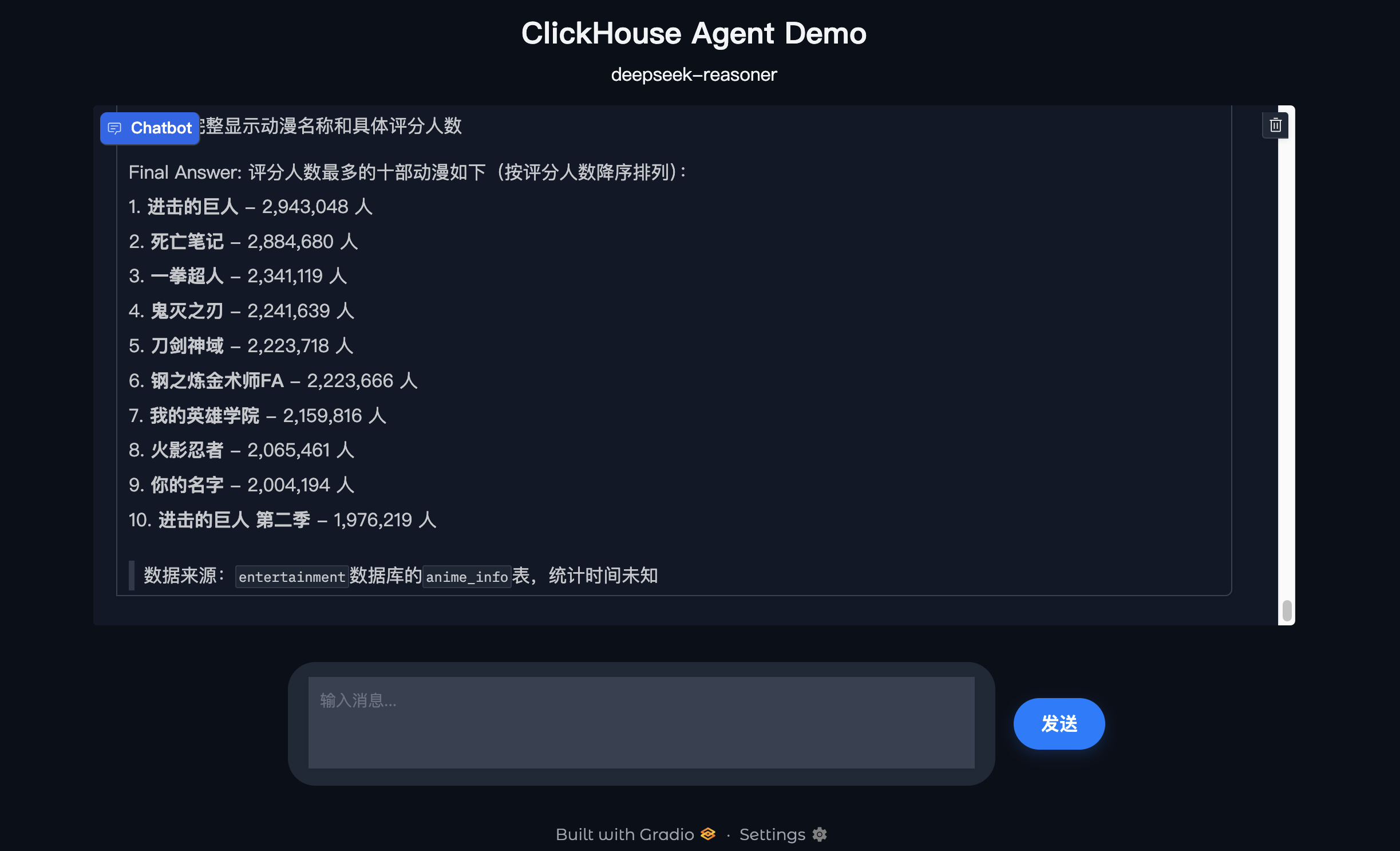
核心实现如下:
from qwen_agent.agents import Assistant, ReActChat
SYSTEM_PROMPT = """
你是一个数据库查询助手,专门帮助用户查询和分析 ClickHouse 数据库中的数据。
规则:
1. 始终确保 SQL 查询的安全性,避免修改数据
2. 以清晰易懂的方式呈现查询结果
"""
class CHAgent:
"""ClickHouse Agent"""
def __init__(self, llm_cfg, db_config=None):
self.llm_cfg = llm_cfg
# ClickHouse 数据库配置
self.db_config = db_config
def create_tools(self):
"""获取工具列表"""
# 数据库配置
host = self.db_config.get('host')
port = self.db_config.get('port')
user = self.db_config.get('user')
password = self.db_config.get('password')
# 工具列表
tools = [
{
"mcpServers": {
"mcp-clickhouse": {
"command": "uv",
"args": [
"run",
"--with",
"mcp-clickhouse",
"--python",
"3.10",
"mcp-clickhouse"
],
"env": {
"CLICKHOUSE_HOST": host,
"CLICKHOUSE_PORT": port,
"CLICKHOUSE_USER": user,
"CLICKHOUSE_PASSWORD": password,
"CLICKHOUSE_SECURE": "false",
"CLICKHOUSE_VERIFY": "false",
"CLICKHOUSE_CONNECT_TIMEOUT": "30",
"CLICKHOUSE_SEND_RECEIVE_TIMEOUT": "30"
}
}
}
},
]
return tools
def create_react_agent(self):
"""创建 ReActChat 模式的 Agent"""
tools = self.create_tools()
return ReActChat(
llm=self.llm_cfg,
name='ClickHouse 数据库助手',
description='ReActChat 模式',
system_message=SYSTEM_PROMPT,
function_list=tools,
)
def ask(self, bot, messages: list) -> str:
"""使用指定的 bot 进行查询"""
response = bot.run_nonstream(messages)
message = response[-1].get('content').strip()
return message
完整代码见 GitHub:luochang212/chat-to-clickhouse